Baopu Lab is a private research institute established by Dr. Bo Gao. The name 'Baopu' (抱朴) originates from the idiom '抱朴守真', signifying the embrace of simplicity and adherence to fundamental truths.
Dr. Bo Gao envisions a research environment stripped of elaborate embellishments, focusing solely on the world's most primitive and fundamental principles. In an era of explosive AI growth where researchers chase trends and quick publications, Dr. Bo Gao chooses to slow down and delve into questions that truly matter.
Currently, Baopu Lab's primary research lies in Artificial Intelligence, not in building larger models or chasing benchmarks, but in understanding the fundamental mechanisms underlying intelligence itself.
Collaborations are welcome if Dr. Gao is interested in your proposal. Email: bmgao@hotmail.com
Softplus Attention with Re-weighting Boosts Length Extrapolation in Large Language Models
This work finally unveils the mystery of Softmax Attention from a computational neuroscience perspective. For years, the AI community has treated Softmax Attention as a black box. Everyone knows it works but no one knows why. This paper reveals that it is essentially a primitive form of neural lateral inhibition. The Softmax attention is a variant of Heeger's Normalisation Model, a canonical computation observed in biological visual cortex that establishes the necessary global competition for stable signal processing.
Based on this computational neuroscience perspective, Dr. Bo Gao introduces the next-generation self-attention model, Softplus Attention with Re-weighting (LSSAR), as an integration of three canonical computational neuroscience models: Divisive Normalisation, Subtractive Inhibition, and Winner-Take-All (WTA) dynamics. First, it uses Divisive Normalisation to enforce global competition. Then, it applies Subtractive Inhibition for coarse noise filtering. Finally, it integrates WTA dynamics for fine-grained selection. This combination results in a coarse-to-fine causal filter that mirrors the brain's own perceptual inference mechanism, fundamentally resolving the long-standing challenges of attention smoothing, attention sinks, and length extrapolation in large scale models.
The results speak for themselves. Beyond mere accuracy improvements in downstream tasks, LSSAR unlocks superior extrapolation capabilities absent in Softmax. It maintains nearly constant validation loss at 16× the training length. In 'needle-in-a-haystack' tests, where standard Softmax collapses to 0% accuracy, LSSAR keeps finding the needle. But the true breakthrough is that LSSAR demonstrates extraordinary reasoning capabilities.
LSSAR Discovers Newton's Laws
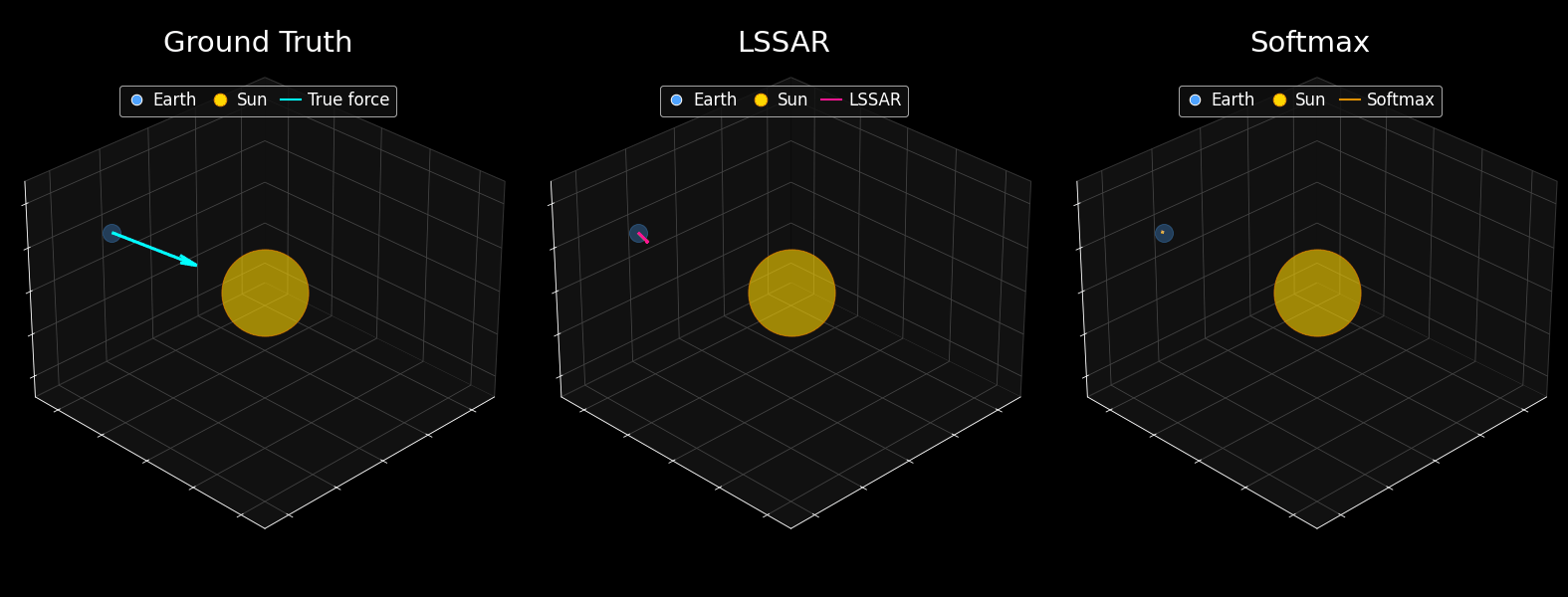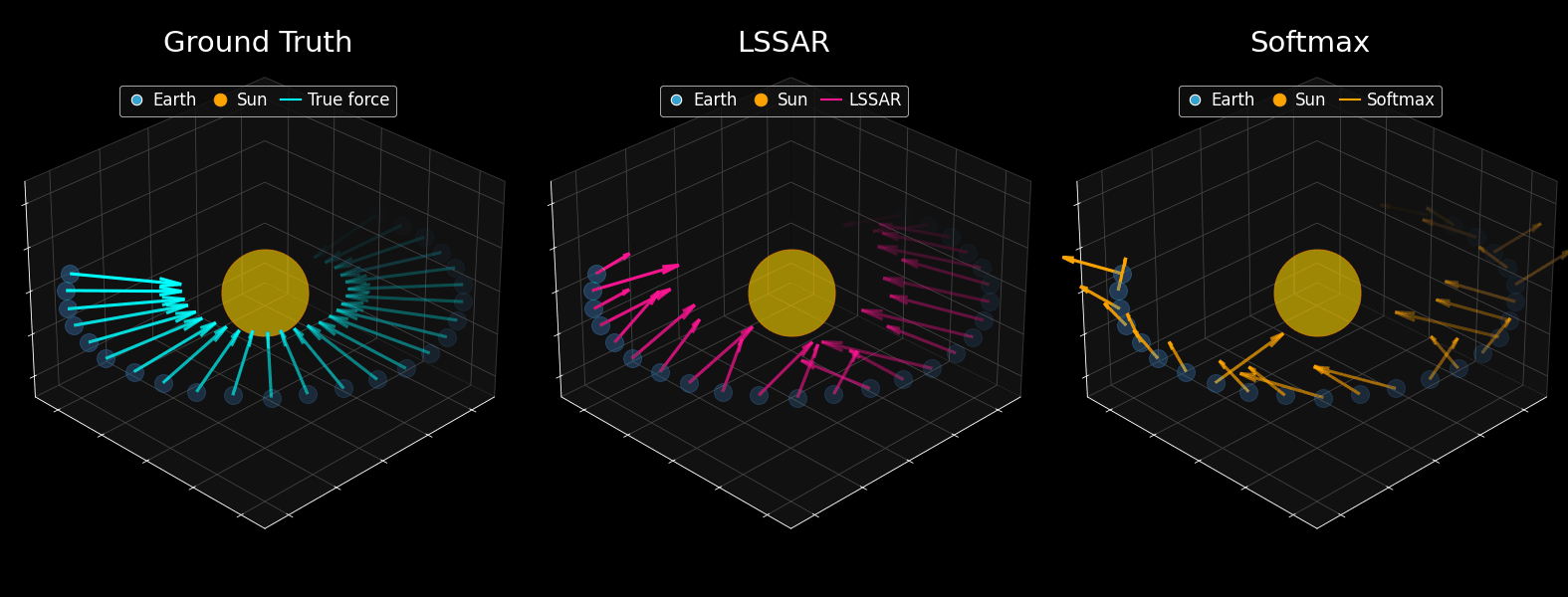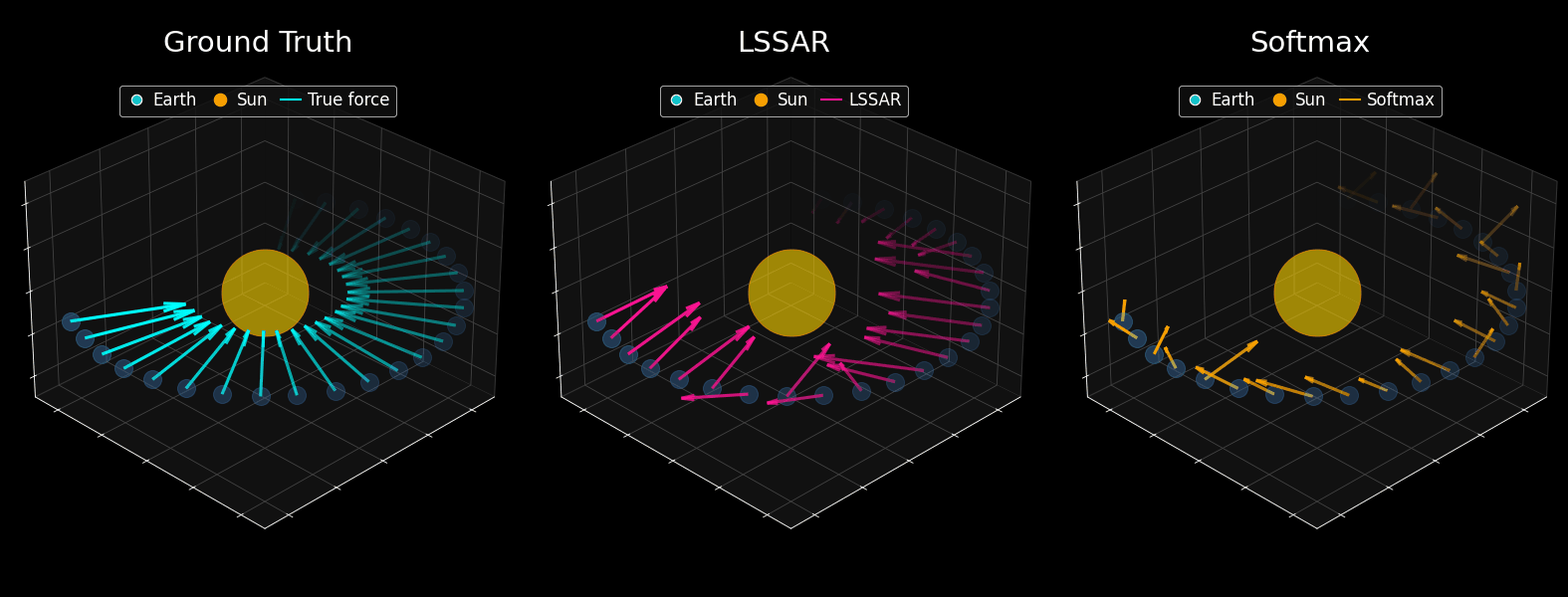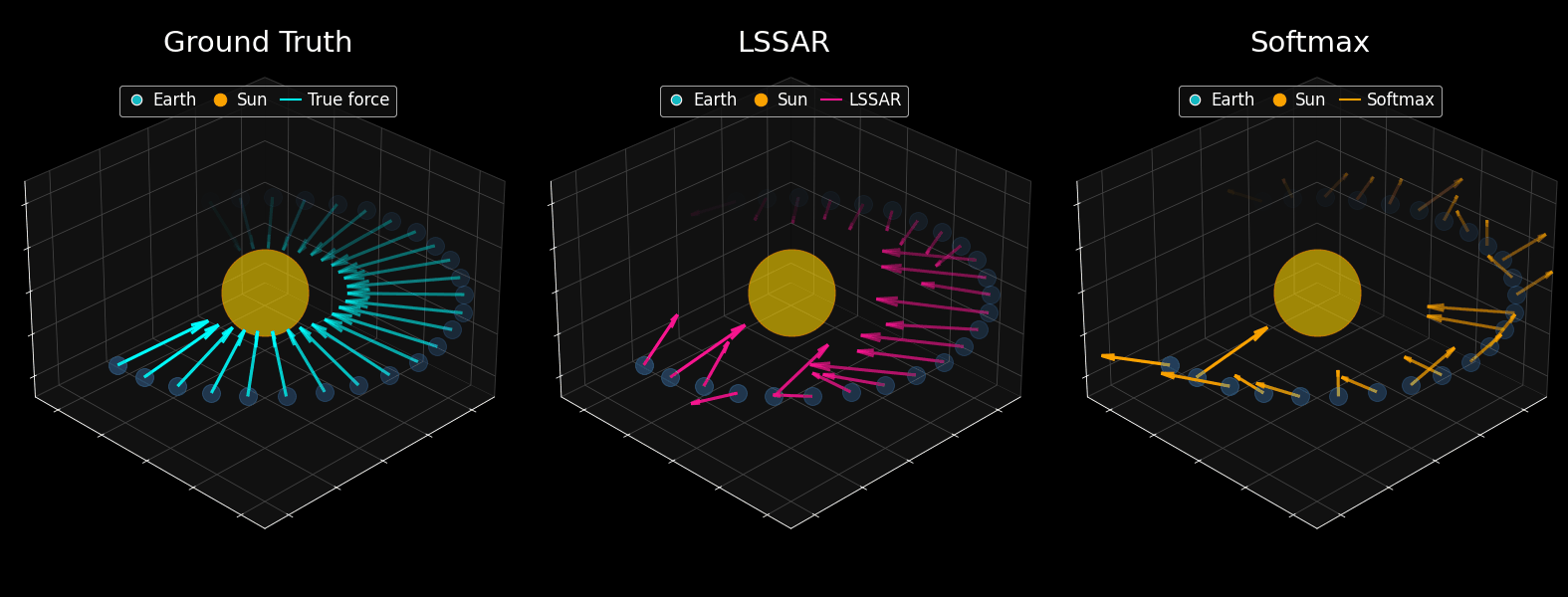
What You're Seeing
Here's a remarkable experiment: a tiny 109M parameter GPT-2 model was trained on 10 million simulated planetary trajectories. The only difference between the two models shown is the attention mechanism, LSSAR versus standard Softmax. After training, symbolic regression was used to extract the mathematical law that best describes the model's force predictions. The results are striking: LSSAR successfully recovers Newton's inverse-square law (F = 27.02 × m/r²), correctly identifying how gravitational force depends on mass and distance. The fitted constant is remarkably close to the theoretical value. Meanwhile, standard Softmax fails entirely, producing physically meaningless equations.
But here's where it gets truly interesting. State-of-the-art trillion-parameter models (o3, Claude 4 Sonnet, and Gemini 2.5 Pro) were also tested on the same task. Despite their vast knowledge, all three failed to discover Newton's law, producing trivial expressions like F ∝ m₁ or nonsensical formulas. A 109M model with the right attention mechanism succeeds where trillion-parameter giants fail. This isn't about scale, it's about having the right inductive biases for causal discovery.
Why This Matters
Perhaps most striking is the paper's implicit challenge to the 'scaling hypothesis.' While mainstream AI research remains fixated on ever-larger models, this work offers a compelling counter-narrative: compression is intelligence. LSSAR's sparse attention functions as a coarse-to-fine causal filter, systematically eliminating noise while distilling the sparse causal structures that govern the data.
The rediscovery of Newton's gravitational law from raw orbital trajectories stands as the ultimate vindication: physical laws are, at their core, sparse causal structures waiting to be unveiled. A model capable of compressing observations into such elegant mathematical forms has achieved something approaching genuine understanding. Dr. Bo Gao contends that this very capacity, to extract sparse, invariant causal mechanisms from noisy observations, represents the fundamental missing piece in modern AI. This breakthrough marks a decisive stride towards constructing authentic World Models and, ultimately, realising Artificial General Intelligence.